A Communication Efficient ADMM‑based Distributed Algorithm Using Two‑Dimensional Torus Grouping AllReduce
Abstract
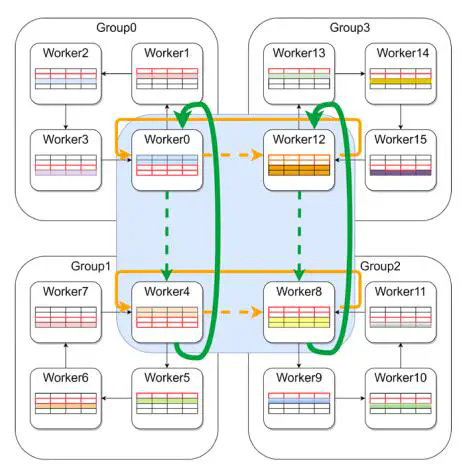
Large-scale distributed training mainly consists of sub-model parallel training and parameter synchronization. With the expansion of training workers, the efficiency of parameter synchronization will be affected. To tackle this problem, we first propose 2D-TGA, a grouping AllReduce method based on the two-dimensional torus topology. This method synchronizes the model parameters by grouping and makes full use of bandwidth. Secondly, we propose a distributed algorithm, 2D-TGA-ADMM, which combines the 2D-TGA with the alternating direction method of multipliers (ADMM). It focuses on sub-model training and reduces the wait time among workers in the synchronization process. Finally, experimental results on the Tianhe-2 supercomputing platform show that compared with the 𝙼𝙿𝙸_𝙰𝚕𝚕𝚛𝚎𝚍𝚞𝚌𝚎, the 2D-TGA could shorten the synchronization wait time by 33%.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.