 Image credit: Unsplash
Image credit: UnsplashAbstract
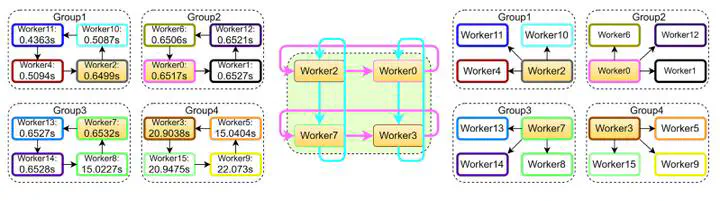
In large-scale distributed machine learning (DML), the synchronization efficiency of the distributed algorithm becomes a critical factor that affects the training time of machine learning models as the computing scale increases. To address this challenge, we propose a novel algorithm called Grouped Sparse AllReduce based on the 2D-Torus topology (2D-TGSA), which enables constant transmission traffic that does not change with the number of workers. Our experimental results demonstrate that 2D-TGSA outperforms several benchmark algorithms in terms of synchronization efficiency. Moreover, we integrate the general form consistent ADMM with 2D-TGSA to develop a distributed algorithm (2D-TGSA-ADMM) that exhibits excellent scalability and can effectively handle large-scale distributed optimization problems. Furthermore, we enhance 2D-TGSA-ADMM by adopting the resilient adaptive penalty parameter approach, resulting in a new algorithm called 2D-TGSA-TPADMM. Our experiments on training the logistic regression model with ‘1 -norm on the Tianhe-2 supercomputing platform demonstrate that our proposed algorithm can significantly reduce the synchronization time and training time compared to state-of-the-art methods.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.