An efficient hybrid MPI/OpenMP parallelization of the asynchronous ADMM algorithm
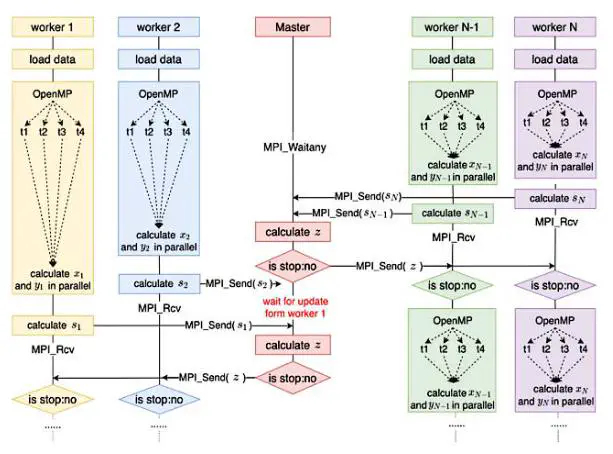 Image credit: Unsplash
Image credit: UnsplashAbstract
Alternating direction method of multipliers (ADMM) is an efficient algorithm to solve large-scale machine learning problems in a distributed environment. To make full use of the hierarchical memory model in modern high-performance computing systems, this paper implements a hybrid MPI/OpenMP parallelization of the asynchronous ADMM algorithm (AH-ADMM). The AH-ADMM algorithm updates local variables in parallel by OpenMP threads and exchanges information between MPI processes, which relieves memory and communication pressure by replacing multi-processing with multi-threading. Furthermore, for the SVM problem, the AH-ADMM algorithm speeds up the calculation of sub-problems through an efficient parallel optimization strategy. This paper effectively combines the features of both algorithm design and programming model. Experiments on the Ziqiang4000 high-performance cluster demonstrate that the AH-ADMM algorithm scales better and run faster than the existing distributed ADMM algorithms implemented by pure MPI. The AH-ADMM can reduce the communication overhead by up to 91.8% and increase the convergence rate by up to 36x. For large datasets, the AH-ADMM can scale well on the cluster which over 129 cores.
Add the publication’s full text or supplementary notes here. You can use rich formatting such as including code, math, and images.